-
Real-time Updates addresses the challenge of delivering immediate notifications and data changes from servers to clients as events occur.
-
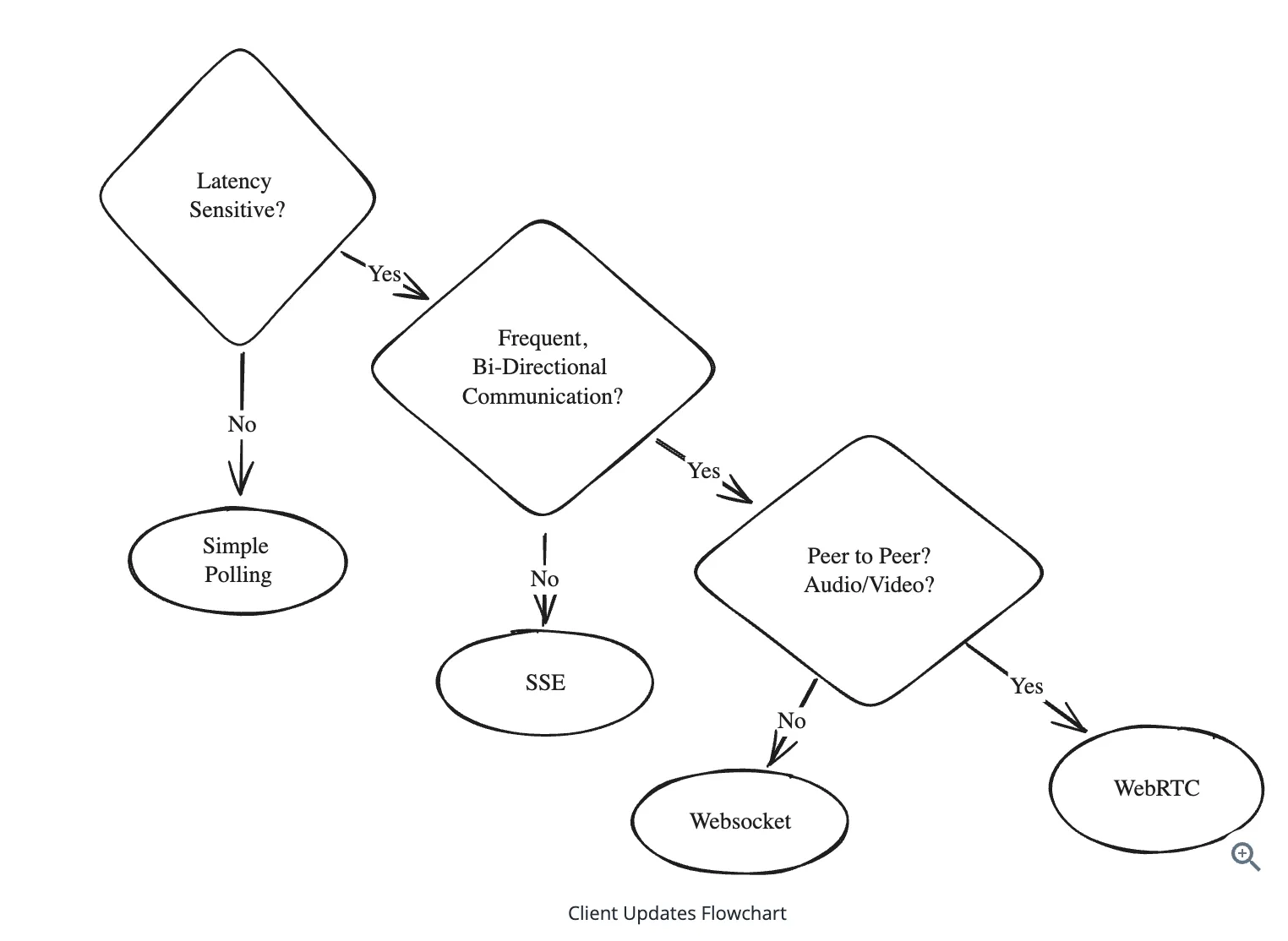
For realtime updates most of the time polling would be the correct approach to implement, simple, easy to use, need not complicate with websockets or pub-sub. Before taking a decision Ask interviewer how real-time it needs to be ?
-
If answer is nearly real-time or fairly responsive then polling is adequate.
-
Eg for Google Docs, if we poll every few milliseconds asking server is there an update, it would result into overwhelming the server with loft of requests.
let’ see what happens under the hood ?
-
docs.api.google.com -> needs to be converted to an IP address, this requires round trip to the server(which is an overhead)
-
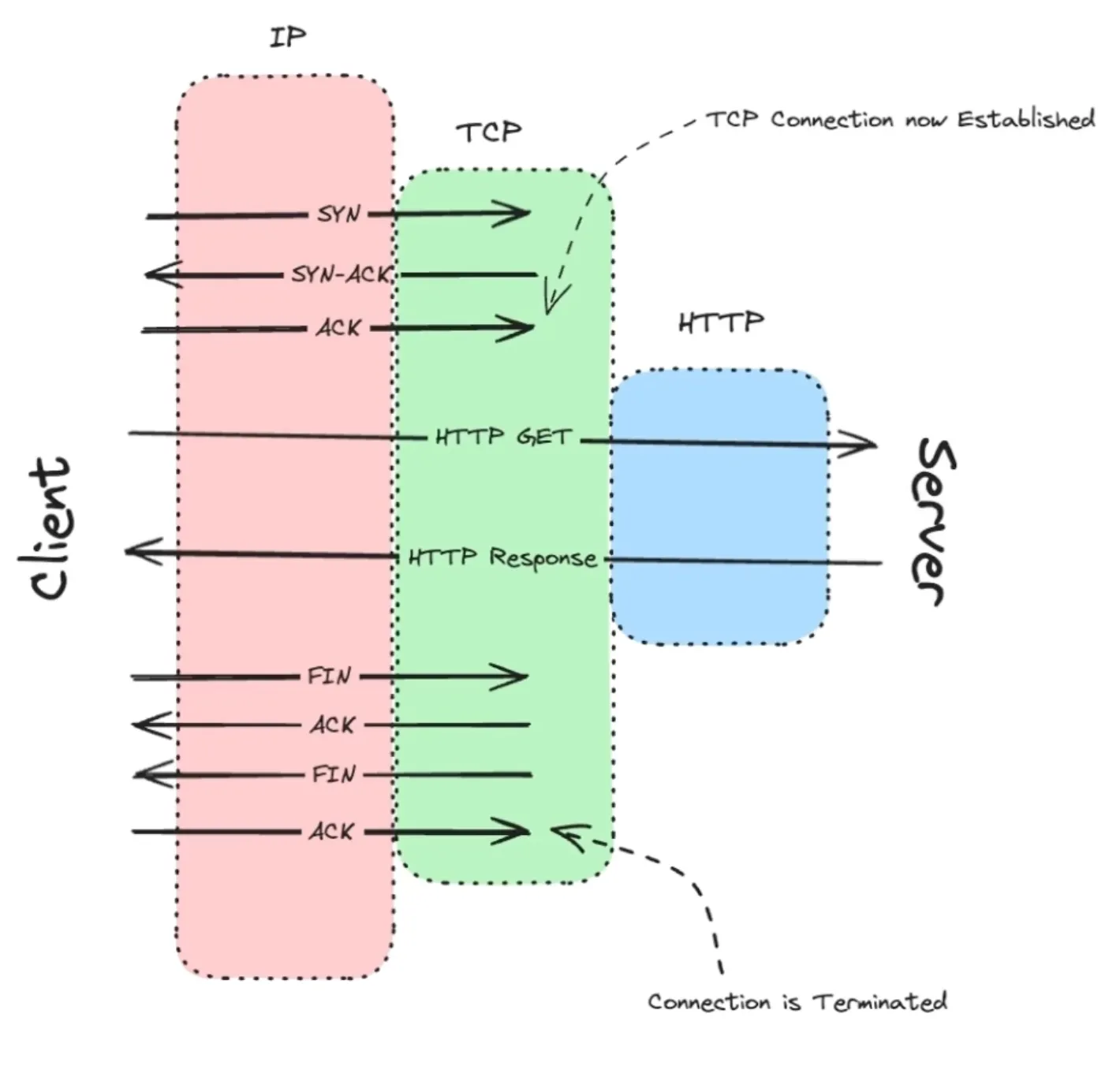
now we establish a TCP connection to the server, TCP requires a 3-way-handshake
-
Now the connection is established.
-
Now when we need to close the connection we need to send a 4-way-handshake.
-
Most of the time say there is no new typing in Google Docs, so we just burn through a lot of networking overhead for nothing.
-
HTTP ; therefore falls short for realtime as it follows request-response cycle, client requests, and server responses and the connection closes.
Networking layers
-
** Network Layer (Layer 3):** At this layer is IP, the protocol that handles routing and addressing. It’s responsible for breaking the data into packets, handling packet forwarding between networks, and providing best-effort delivery to any destination IP address on the network. However, there are no guarantees: packets can get lost, duplicated, or reordered along the way.
-
Transport Layer (Layer 4): At this layer, we have TCP and UDP, which provide end-to-end communication services:
-
TCP is a connection-oriented protocol: before you can send data, you need to establish a connection with the other side. Once the connection is established, it ensures that the data is delivered correctly and in order. This is a great guarantee to have but it also means that TCP connections take time to establish, resources to maintain, and bandwidth to use.
-
UDP is a connectionless protocol: you can send data to any other IP address on the network without any prior setup. It does not ensure that the data is delivered correctly or in order. Spray and pray!
-
-
Application Layer (Layer 7): At the final layer are the application protocols like DNS, HTTP, Websockets, WebRTC. These are common protocols that build on top of TCP to provide a layer of abstraction for different types of data typically associated with web applications
-
Load balancers distribute incoming requests across these servers to ensure even load distribution and high availability. There are two main types of load balancers you’ll encounter in system design interviews: Layer 4 and Layer 7.
Layer 4 Load Balancers - operate at the transport layer (TCP/UDP). They make routing decisions based on network information like IP addresses and ports, without looking at the actual content of the packets. - The effect of a L4 load balancer is as-if you randomly selected a backend server and assumed that TCP connections were established directly between the client and that server — this mental model is not far off
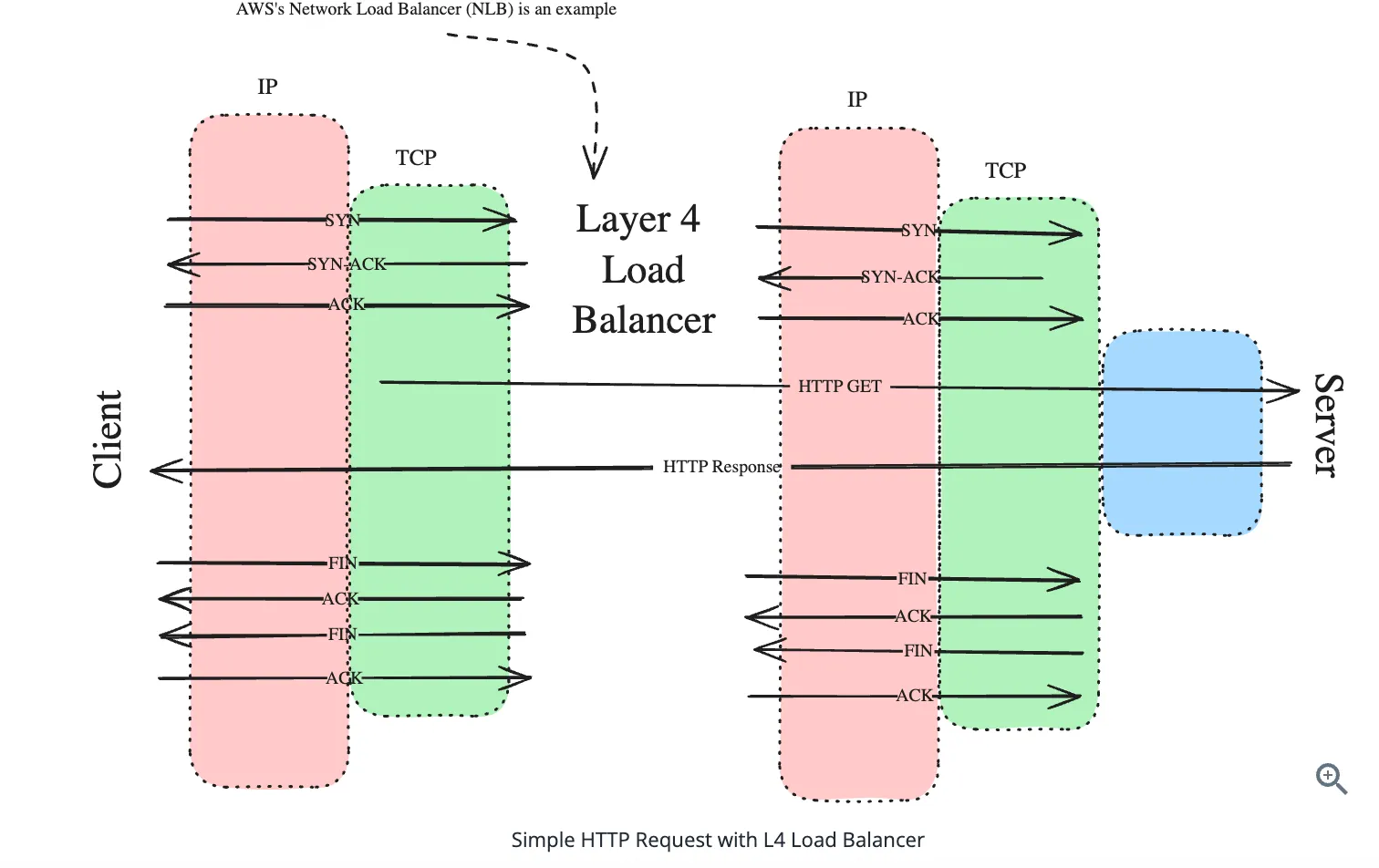 Key characteristics of L4 load balancers:
Key characteristics of L4 load balancers:- Maintain persistent TCP connections between client and server.
- Fast and efficient due to minimal packet inspection.
- Typically used when raw performance is the priority.
Layer 7 Load Balancers Key characteristics of L7 load balancers:
- Terminate incoming connections and create new ones to backend servers
- Can route based on request content (URL, headers, cookies, etc.)
- More CPU-intensive due to packet inspection.
Solutions
When systems require real-time updates, push notifications, etc, the solution requires two distinct pieces:
- The first “hop”: how do we get updates from the server to the client?
- The second “hop”: how do we get updates from the source to the server?
Long Polling
-
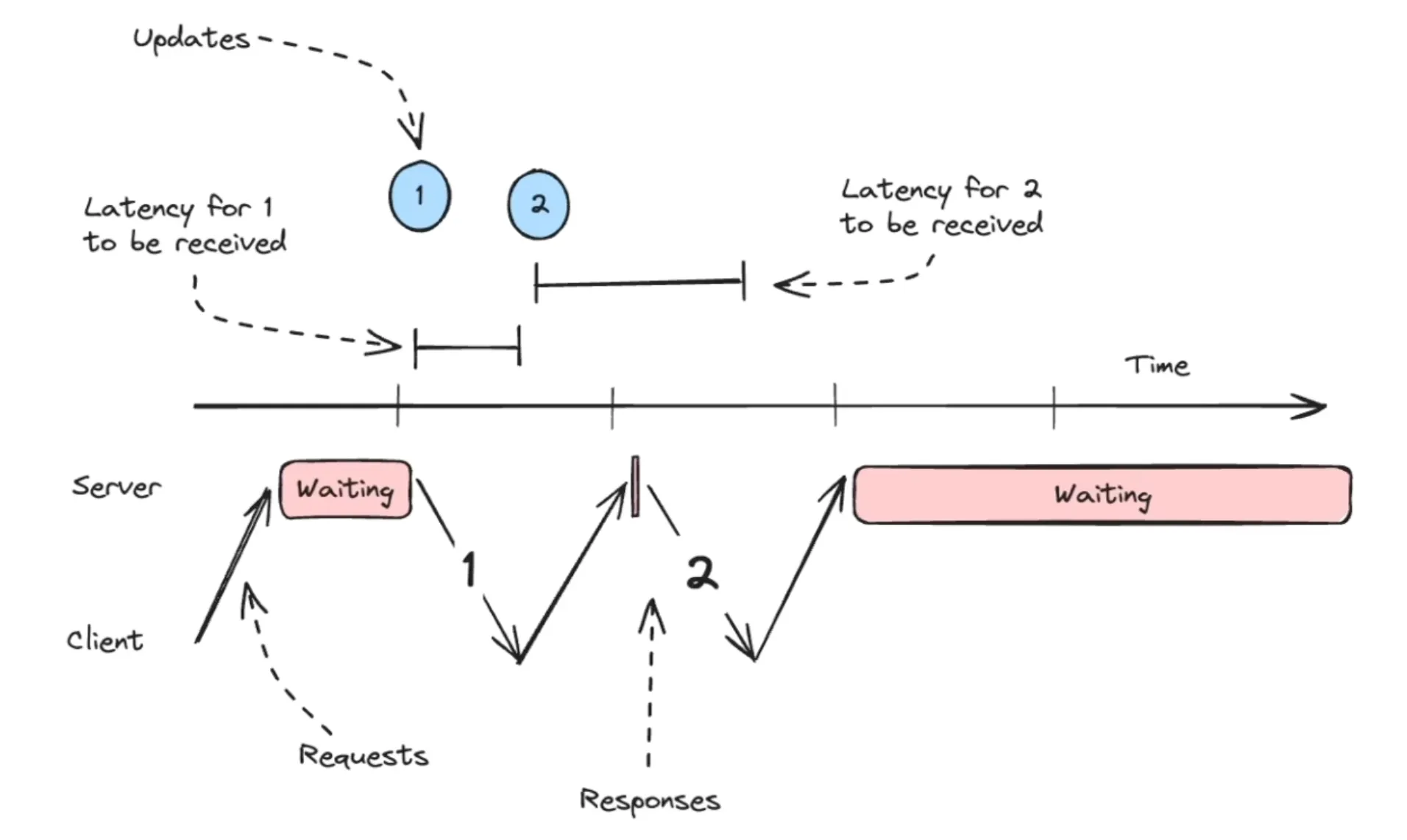
In case of long polling the server holds the request open until data is available or timeout occurs.
-
This cuts down the no of times when the server has to reply no updates when nothing has really changed. But server has to process a request for large amt of time.
-
It also introduces extra latency between client and server.
-
here for the second response we have an extra latency, because the client had to make the request back to get the update.
Note: Not suitable when we need to send high frequency updates, near to one other back to client. (refer above eg)
SSE (Server Sent Events)
- The idea behind SSE is that HTTP response don’t have to come in big packet, and there is a special chunked encoding response type that makes browser sit around and wait for more data to come.
- SSE is built on top of this and most browsers have formal support, the browser side is called event source.
- Good option through interview standpoint, to send high frequency data.
- With SSE, we can send multiple responses down the same HTTP response, basically simulating each of the event we want to send to our client, each of the push notifications.
- Disadv;
- One-way communication only.
- Limited browser support (not an issue for modern browsers).
- Browsers limit the number of concurrent connections per domain, meaning you may only be able to have a few SSE connections per domain.(6 per-domain connections)
WebSockets
- Websockets are abstraction over TCP channel and is a stateful connection, built on top of TCP.
- Here we can send bytes in either direction, doesn’t follow request-response cycle..
- With websockets we might have our connection open for hours, and our infra needs to support it.
- Can be used when we have bidirectional communication and latency is low. If there is a case where only we are sending msg to server than SSE works pretty well.
- Recommended to use L4 load balancer(for middleware infra) , a layer 7 balancer is going to do things like look at http packets and redirect them to various services, but we don’t have that functional requirement here because we can’t actually redirect websocket msg to different services.
- L4 load balancers will support websockets natively since the same TCP connection is used for each request, L7 load balancers aren’t guaranteeing we’re using the same TCP connection for each incoming request.
How it works:
1. Initial HTTP Connection: A WebSocket connection begins with a standard HTTP handshake between the client and server.
2. TCP Connection Establishment:
This handshake utilizes an existing, persistent TCP connection to establish the communication.
3. Protocol Upgrade:
The server then performs a protocol upgrade, transitioning the connection from HTTP to the WebSocket protocol.
4. Full-Duplex Channel:
Once upgraded, the connection becomes a fully bidirectional and stateful channel, allowing both the client and server to send data at any time over the same TCP connection.
Why it matters:
-
Efficiency:
Building on TCP’s established connection avoids the overhead of constantly opening and closing new connections for every small data exchange, which was a common issue with older HTTP polling methods.
-
Real-Time Communication:
This persistent, low-overhead connection is ideal for applications requiring real-time updates and bidirectional communication, such as gaming, chat applications, and financial data feeds.
-
Leverages TCP’s Reliability:
By relying on TCP, WebSocket benefits from TCP’s built-in reliability features, such as error checking, flow control, and ordered delivery of data.
WebRTC
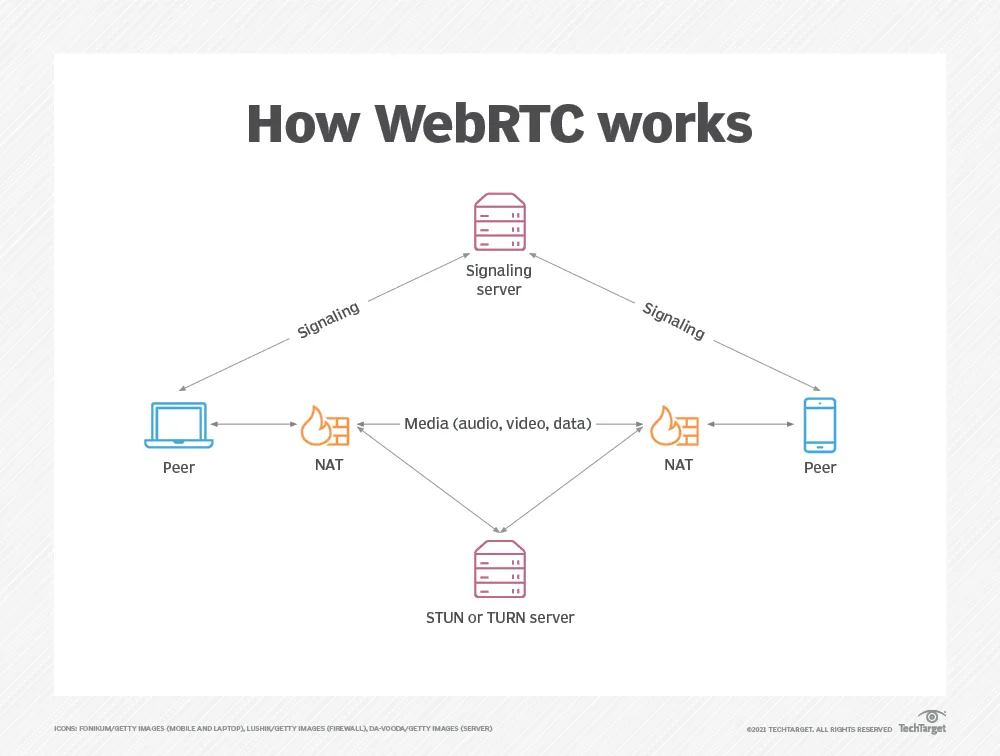
- Should be used where clients need to talk to each other frequently, great for scenarios like video/audio calls, screen sharing and gaming.
- Adv : Direct peer communication, Lower Latency, Native audio/video support
- DisAdv : Complex setup, Requires signalling server, NAT/firewall issues
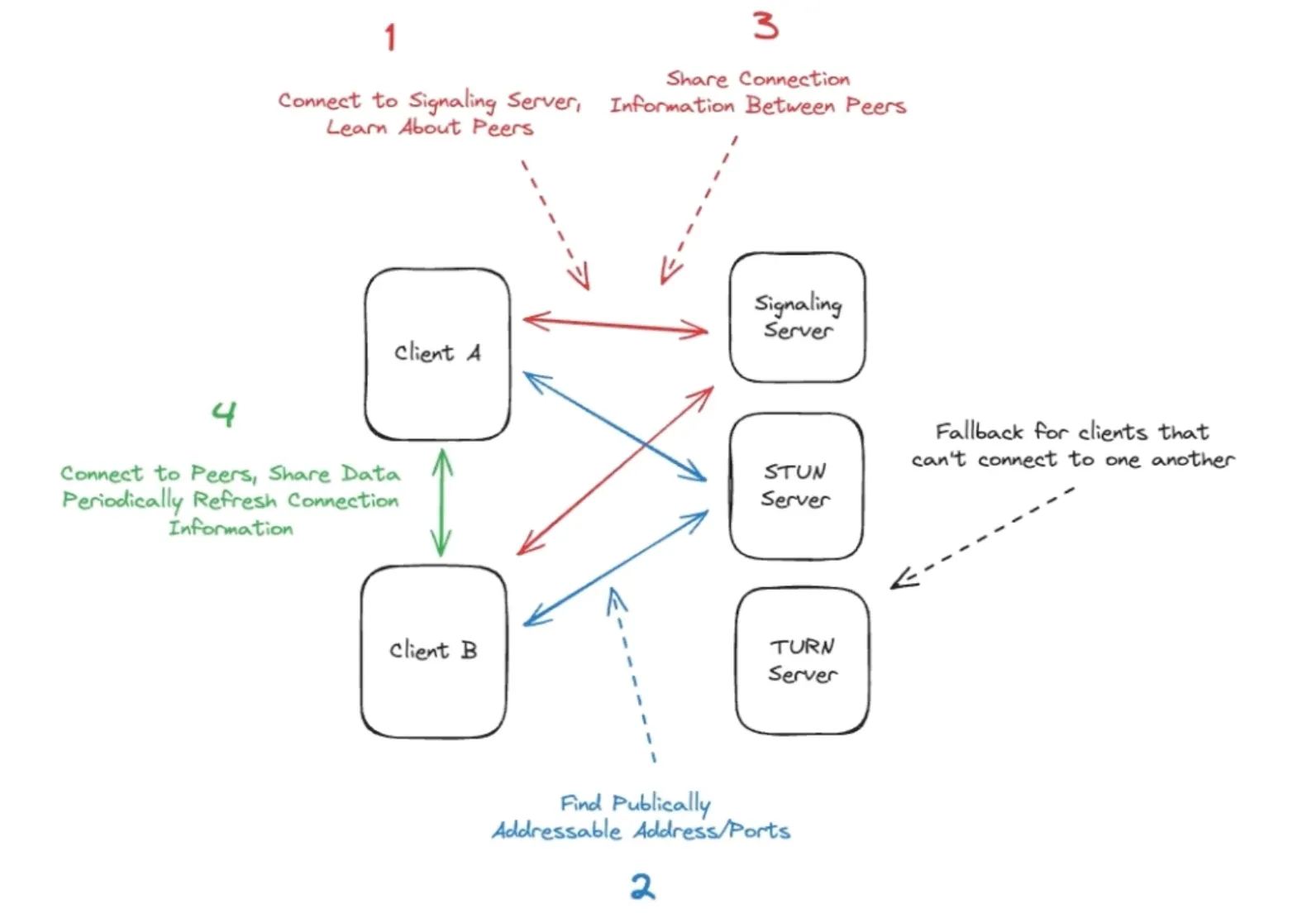
-
Peers discovers each other through signalling server
-
Exchange connection Info
-
Establish peer connection using STUN/TURN server
- STUN: “Session Traversal Utilities for NAT” is a protocol and a set of techniques like “hole punching” which allows peers to establish publically routable addresses and ports.
- TURN: “Traversal Using Relays around NAT” is effectively a relay service, a way to bounce requests through a central server which can then be routed to the appropriate peer.
-
Stream audio/video or send data directly
-
NAT (Network Address Translation)
- It’s the process of modifying IP addresses (and sometimes ports) in packet headers while routing them.
- NAT is usually done by a router or firewall sitting between a private network (LAN) and the public internet.
-
Why do we need NAT?
-
IPv4 address shortage
- There aren’t enough public IPv4 addresses for every device.
- NAT allows many devices to share one public IP.
-
Security
- NAT hides internal IPs (e.g.,
192.168.x.x,10.x.x.x) from the outside world. - External hosts only see the NAT device’s public IP.
- NAT hides internal IPs (e.g.,
TLDR;
Server-Side Push/pull
- how we can propagate updates from the source to the server ? When it comes to triggering, there’s three patterns that we’ll commonly see:
- Pulling via Polling
- Pushing via Consistent Hashes
- Pushing via Pub/Sub
Pulling via Polling
- Have a database where we can store the updates (e.g. all of the messages in the chat room), and from this database our clients can pull the updates they need when they can,
- When to use ?
- Pull-based polling is great when you want your user experience to be somewhat more responsive to changes that happen on the backend, but responding quickly is not the main thing. Generally speaking
- Things to Discuss ?
- Talk about how you’re storing the updates.
- If you’re using a database, you’ll want to discuss how you’re querying for the updates and how that might change given your load.
Pushing via Consistent Hashes
- Problem ?
- The client has persistent connection to one server and that server is responsible for sending updates to the client.
- For our chat application, in order to send a message to User C, we need to know which server they are connected to.
-
Simple Hashing (Approach 1)
- Central service that knows how many servers there are N and can assign them each a number 0 through N-1 (Zookeeper)
- Randomly connect to any of the servers and have that server redirect them to the appropriate server based on internal data.
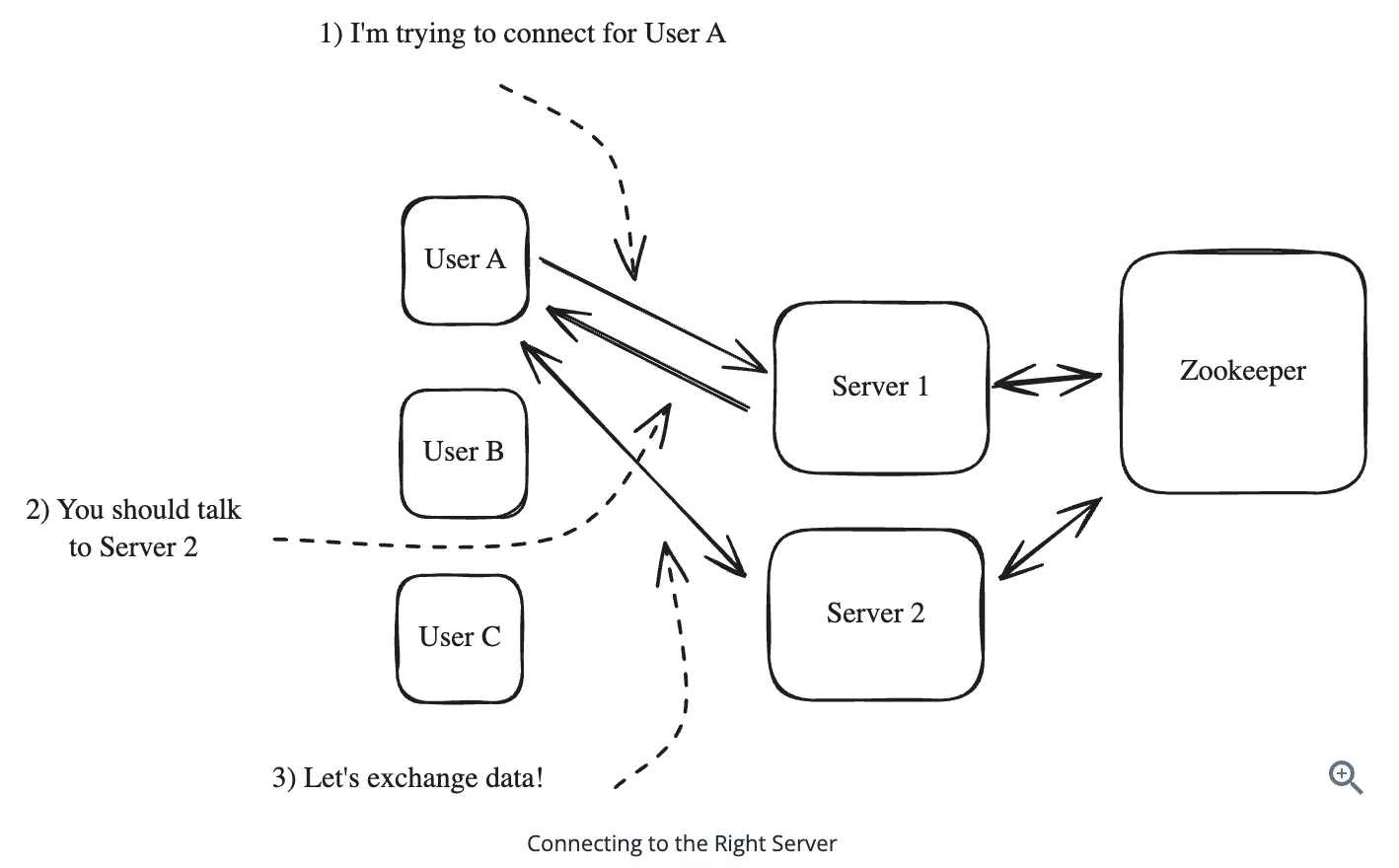
When a client connects, the following happens: 1. The client connects to a random server. 2. The server looks up the client’s hash in Zookeeper to figure out which server is responsible for them. 3. The server redirects the client to the appropriate server. 4. The client connects to the correct server. 5. The server adds that client to a map of connections.
DisAdv:
- Hashing approach works great when N is fixed, but becomes problematic when we need to scale our service up or down. With simple modulo hashing, changing the number of servers would require almost all users to disconnect and reconnect to different servers - an expensive operation that disrupts service.Consistent Hashing solves this problem
Consistent Hashing (Approach 2)
- Solves this by minimizing the number of connections that need to move when scaling. It maps both servers and users onto a hash ring, and each user connects to the next server they encounter when moving clockwise around the ring.
-
When to Use Consistent Hashing
Consistent hashing is ideal when you need to maintain persistent connections (WebSocket/SSE) and your system needs to scale dynamically. It’s particularly valuable when each connection requires significant server-side state that would be expensive to transfer between servers.
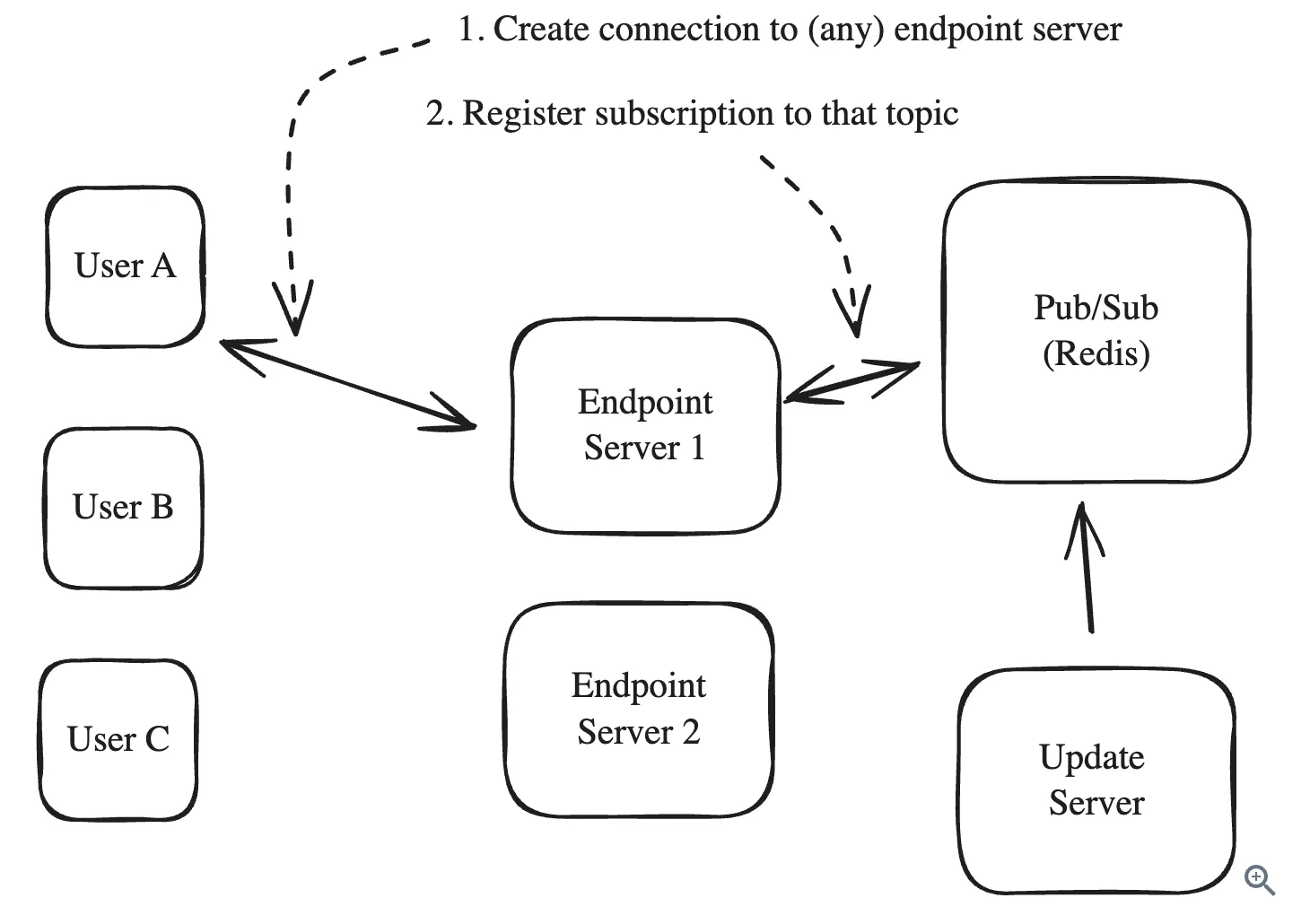
Pushing via pub/sub
-
eg: kafka or redis
-
Working:
- Persistent connections are now made to lightweight servers which simply subscribe to the relevant topics and forward the updates to the appropriate clients, endpoint servers
- Adv:
- Maintaining load on endpoint server is easy, use load balancer with least-connection strategy
- DisAdv:
- We don’t know whether subscribers are connected to the endpoint server, or when they disconnect.
- The Pub/Sub service becomes a single point of failure and bottleneck.
- We introduce an additional layer of indirection which can add to latency.
-
When to use ?
- need to broadcast updates to a large number of clients.
- we don’t need to respond to connect/disconnect events or maintain a lot of state associated with a given client.
- latency impact is minimal (<10ms).