Consistent Hashing
-
One of the most amazing and popular algorithm out there and the only problem it solves is Data ownership.
-
It will not transfer data for us it is not a service in “itself”
-
Consistent Hashing applies to any scenarios where you need to distribute data across cluster of servers. Used in Cassandra, DynamoDB and CDNs.
-
In infra-focused interviews where you ‘re asked to design distributed system from scratch, common topic/scenarios:
- Design distributed database
- Design distributed Cache
- Design distributed message broker
Understanding Consistent Hashing
- Say we’re having a stateful distributed storage
- node store the data
- proxy forwards the request to a node
- end-user/client talks to node

- When the number of node changes the proxy will change the no of functions and it would not become fn%2.
- Now all the keys would need to be re-evaluated and moved to the correct node (involves a lot of data transfer)
Hash Fn (SHA128)
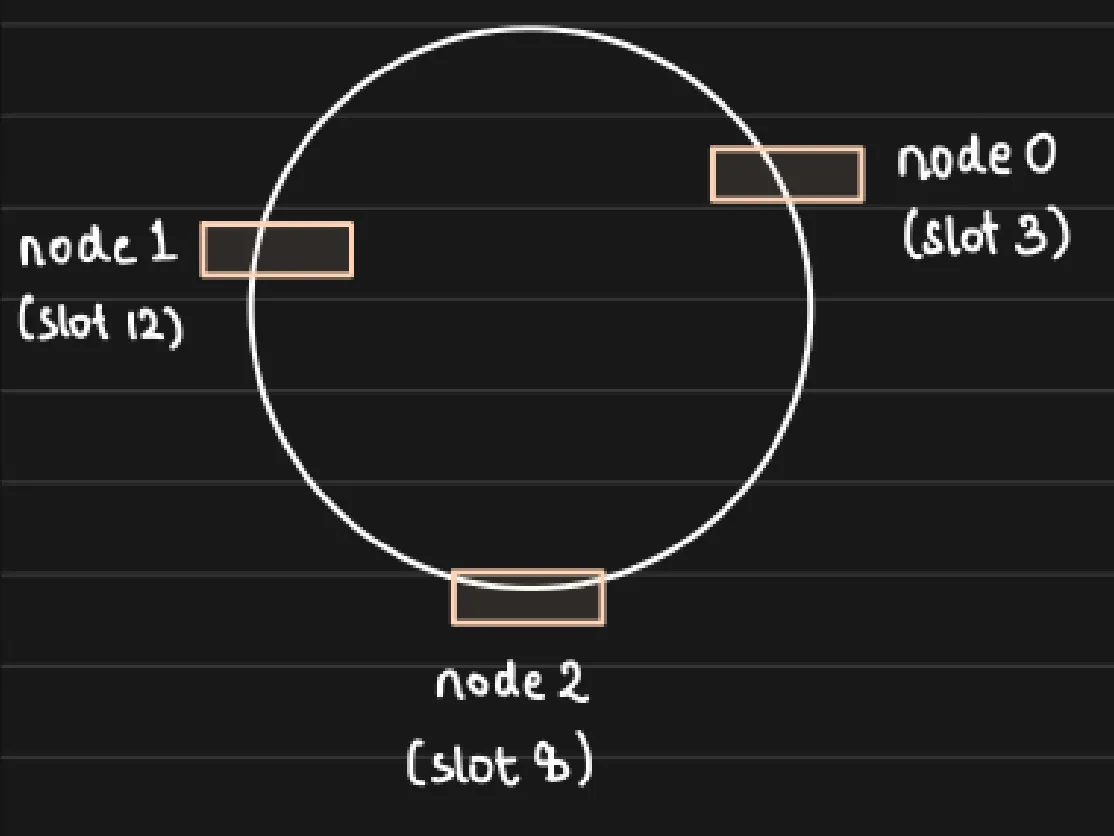
- Given hash fn are cyclic we can visualize it as a ring of integers, every node occupies one slot in the integer, the slot is calculated by passing node’s IP to hash fn.
Scaling Up
- When we add a new node to the “ring” Say node3 hashes to slot 1, The keys that hashed between slot 12 and slot will now be “owned” by node 3 instead of node O.
- Other keys continue to remain at the respective nodes - Minimal Data Movement
- Operationally we have to
- snapshot node 0
- create node 3
- delete unwanted keys
Scaling Down
- Say we scale down and rетоvе node1. All the keys that were owned by Node O will now be owned by Node 2 (next in the ring) -> Minimal Data Transfer
- Operationally we have to
- copy everything from Node 0 to Node 1
- remove node 2 from the ring
- delete node 2
Virtual Nodes
- We had to move all events that were stored on database 2 to database 3. Now database 3 has 2x the load of database 1 and database 4.
- We’d much prefer if we could spread the load more evenly so database 3 wasn’t overloaded.
- The solution is to use what are called “virtual nodes”
- Instead of putting each database at just one point on the ring, we put it at multiple points by hashing different variations of the database name.
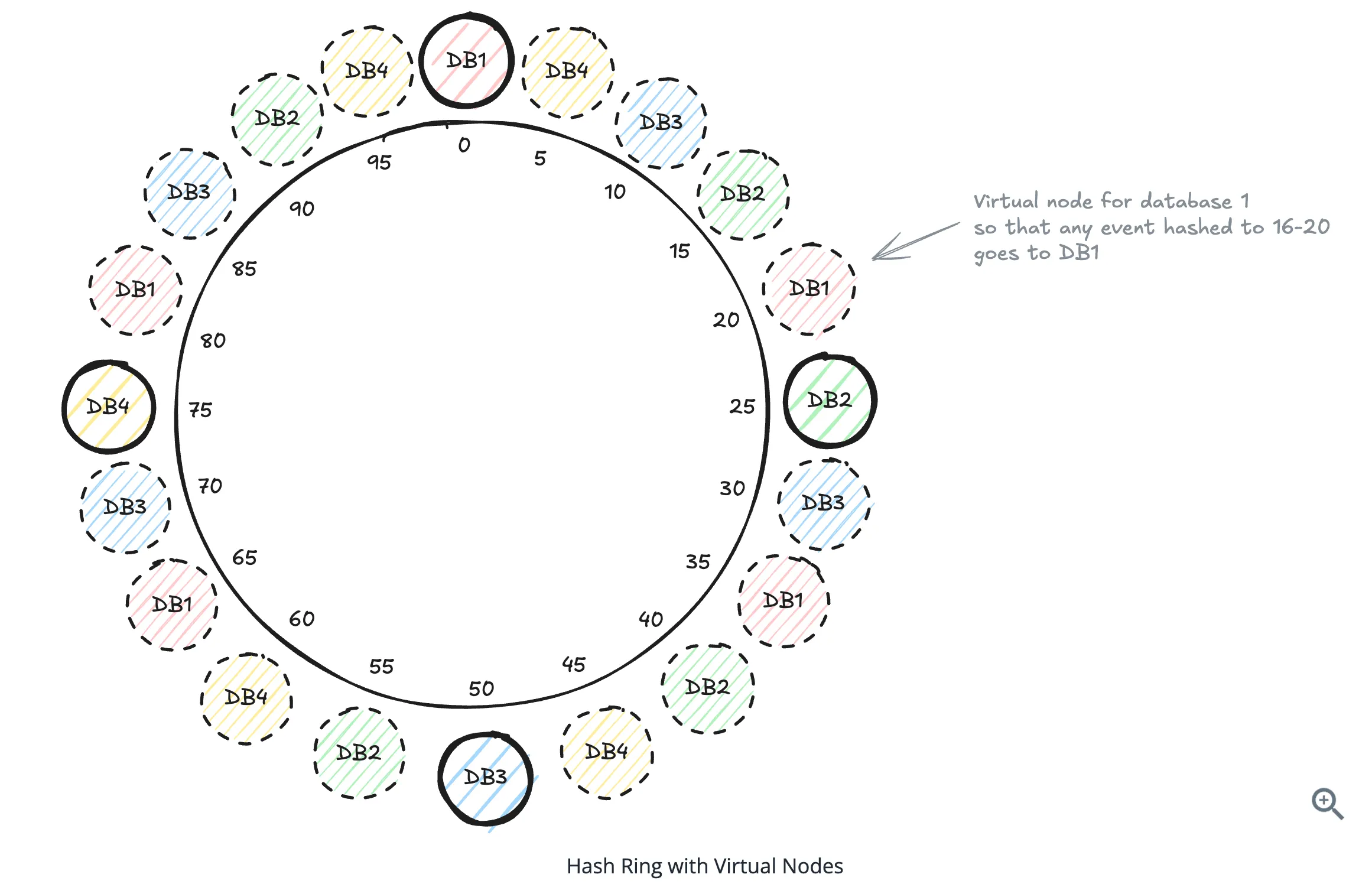
- The more the virtual nodes you use per database, the more evenly distributed the load becomes.